Some time ago, I built a DynDNS solution using AWS CDK. It worked well, but the ecosystem has evolved. Here’s an updated version—fully serverless, more secure, and with extended functionality.
Improvements over the previous version
Enhanced IP Reflection with MaxMind DB
The /get endpoint now provides detailed information about your IP address, including:
This makes the service useful for diagnostics, API integrations, or privacy checks.
Consistent TypeScript Usage
The previous Python implementation has been replaced entirely with TypeScript, including Lambda functions. Using a unified tech stack simplifies maintenance, promotes type consistency, and reduces complexity. AWS is phasing out Python 3.8. The updated version now runs on Node.js 22, ensuring long-term AWS support and security.
Cost Efficiency
This solution runs entirely within the AWS free tier for most personal uses. I’ve tested it myself with frequent API checks (every 15 seconds), and costs remain minimal. The only unavoidable expense is Route53, approximately $0.50 monthly, plus annual domain fees.
Technical Overview
The service exposes two main endpoints:
/get: Provides detailed information about your public IP.
/update: Securely updates DNS records with your current IP.
Initial Configuration
Upon first deployment, the CDK stack creates a DynamoDB table (ServerlessDynamicDnsStack-ConfigTable{randomId}). This table stores the configuration:
domain: e.g., home.yourdomain.com
hostedZoneId: Route53 hosted zone ID
secret: A secure shared secret (password), ideally randomly generated.
Example Configuration:
domain
hostedZoneId
secret
home.yourdomain.com
Z0123456789ABCDEF
(random_secret)
Secure DNS Update Mechanism
To automatically update your DNS record, you’ll need a small script that calculates an authentication hash and then calls the /update endpoint.
constHOSTED_ZONE_ID = "ZXXXXXXXXXXXXXX"; // Replace with your actual Hosted Zone ID constSHARED_SECRET = "your_shared_secret"; // Replace with your actual shared secret constHOSTNAME = "home.yourdomain.com"; // The domain you want to update
When it comes to hosting a static website—be it a single-page app or a feature-rich client-side framework—AWS provides an extremely reliable and cost-effective solution using S3 and CloudFront. With the AWS Cloud Development Kit (CDK), we can define all necessary resources in TypeScript (or other supported languages) and deploy them as Infrastructure as Code (IaC), making the process repeatable and easily maintainable.
This post will walk you through:
Setting up your local environment
Initializing a new CDK project
Creating a custom CDK construct for hosting a static site (S3 + CloudFront + Route53)
Deploying your website step-by-step (build → synth → deploy)
Prerequisites & Setup
1. AWS Account
You’ll need an AWS account to deploy your website. If you don’t have one yet, head over to aws.amazon.com to sign up. It’s free to create an account, and you get 12 months of free tier access to many services.
2. Domain and Hosted Zone
For a custom domain such as my private timhartmann.de, you need a Hosted Zone in Route53. This is a requirement for setting up the DNS records and getting a valid SSL certificate via AWS Certificate Manager.
If you’ve purchased a domain directly through AWS, the system automatically sets up a Hosted Zone for you.
If you own a domain elsewhere, you’ll need to manually create and configure a Hosted Zone in Route53, then update your domain registrar’s name servers to use Route53.
3. AWS CLI and CDK Installation
If you haven’t installed the AWS Command Line Interface (CLI) yet, you can do so by following the AWS CLI installation docs. Once installed, run:
/** * Construct to create a static website hosted on S3 with CloudFront distribution and Route 53 DNS record * * if apiGwUrl is provided, it will be injected as json file to the frontend package */ exportclassStaticWebsiteConstructextendsConstruct { constructor( scope: Construct, id: string, props: StaticWebsiteProps ) { super( scope, id );
// Set up the hosted zone and DNS const hostedZone = HostedZone.fromHostedZoneAttributes( this, 'HostedZone', { hostedZoneId: props.hostedZoneId, zoneName: props.domainName, } );
// Create a certificate for CloudFront (must be in us-east-1) // This Construct will be marked as deprecated, but there is no alternative yet // It will still work for the time being until CDKv3 is released const certificate = newDnsValidatedCertificate( this, 'WebsiteCertificate', { domainName: props.domainName, hostedZone: hostedZone, region: 'us-east-1', subjectAlternativeNames: props.aliasDomainNames, } );
// Create a CloudFront distribution using the S3 bucket as origin with OAI const distribution = newDistribution( this, 'Distribution', { defaultBehavior: { origin: S3BucketOrigin.withOriginAccessControl( websiteBucket, { originAccessLevels: [ AccessLevel.READ, AccessLevel.LIST ], } ), compress: true, }, domainNames: [ props.domainName, ...( props.aliasDomainNames ?? [] ) ], certificate: certificate, defaultRootObject: 'index.html', errorResponses: [ { httpStatus: 404, responseHttpStatus: 200, responsePagePath: '/index.html', ttl: Duration.seconds( 0 ), }, ], } );
// Create a DNS record pointing to the CloudFront distribution newARecord( this, 'AliasRecord', { zone: hostedZone, target: RecordTarget.fromAlias( newCloudFrontTarget( distribution ) ), } );
for ( const alias of props.aliasDomainNames ?? [] ) { newARecord( this, `AliasRecord-${ alias }`, { zone: hostedZone, target: RecordTarget.fromAlias( newCloudFrontTarget( distribution ) ), recordName: alias, } ); }
// Prepare website assets (frontend package and optional API endpoint) const websiteAssets = [ Source.asset( props.assetPath ) ];
// Deploy the assets to the S3 bucket and invalidate CloudFront cache if needed newBucketDeployment( this, 'WebsiteDeployment', { sources: [ ...websiteAssets ], destinationBucket: websiteBucket, destinationKeyPrefix: '/', distributionPaths: [ '/*' ], distribution: distribution, } ); } }
Usage in a CDK Stack
Here’s an example of how to use this construct inside a CDK Stack. You might place this in lib/MyWebsiteStack.ts:
Make sure to substitute the hostedZoneId with your actual Hosted Zone ID. If you’re copying from Route53, you’ll see it labeled as “Hosted Zone ID.”
Deploying the Stack
When we initialized the CDK project, it created a bin folder with a TypeScript file, named like your project, that defines the infrastructure to deploy. This file is the entry point for your CDK app and is where you define the stacks to deploy. This example only has a single Stack.
const app = new cdk.App(); newTimHartmannDeStack(app, 'TimHartmannDeStaticPageStack', { env: { account: process.env.CDK_DEFAULT_ACCOUNT, region: process.env.CDK_DEFAULT_REGION, // or specify your region here, e.g., 'us-east-1' }, });
Assuming you already ran cdk init and have your project structure in place, you can follow these steps anytime you change either the infrastructure code (e.g., the CloudFront distribution) or your actual website files:
Update your website files in the site-contents folder.
Build (if you have a build step):
1
npm run build
This compiles your TypeScript code.
Synthesize your CloudFormation template:
1
cdk synth
This produces the final CloudFormation stack.
Deploy to AWS:
1
cdk deploy
CDK will zip up and upload the contents from site-contents into the S3 bucket and create or update any AWS resources defined in our construct. After the deployment finishes, you’ll have a fully functioning static website available over HTTPS at your custom domain!
Why CloudFront?
Using CloudFront in front of your S3 bucket offers several benefits:
Global Edge Locations: Your content is served from edge caches around the world, resulting in faster load times.
Security & SSL: CloudFront handles SSL certificates from AWS Certificate Manager, ensuring your site is always served over HTTPS.
Cost-Effectiveness: Storing static assets in S3 is cheap, and you pay only for what you use in CloudFront.
Scalability & Reliability: Automatically handles traffic spikes without you having to manage any servers or capacity.
Conclusion
Deploying a static website with AWS CDK is straightforward and powerful. By treating your infrastructure as code, you get repeatability, version control, and the ability to continuously evolve your stack. With CloudFront’s caching and Route53’s DNS integration, your website is served quickly and reliably from a globally distributed network.
Try it out for personal projects or even for enterprise-grade frontends that don’t require complex server-side logic. If you have any questions or run into any issues, feel free to drop me a message on GitHub or LinkedIn!
When working with Python, particularly in applications involving timed or repeated execution of functions, the built-in options can sometimes feel a bit limiting. To enhance flexibility and control, I’ve crafted a SetInterval class, modeled after JavaScript’s setInterval method but adapted for Python’s threading model. This post will explore this utility class, diving into its structure and use cases.
The Class Explained
The purpose of this is to repeatedly execute a function at specified intervals. This is achieved using Python’s threading.Timer class, which is part of the standard library. Here’s a breakdown of the class components:
classSetInterval: """ A class that mimics the JavaScript setInterval method for Python, using threading. Attributes: func (Callable): The function to be executed repeatedly. sec (float): Time interval between function executions. args (list, optional): Positional arguments for the function. kwargs (dict, optional): Keyword arguments for the function. """ def__init__(self, func, sec, run_now=False, args=None, kwargs=None): self.func = func self.sec = sec self.args = args if args isnotNoneelse [] self.kwargs = kwargs if kwargs isnotNoneelse {} self.thread = None self.start(run_now)
defstart(self, run_now=False): """ Starts or restarts the timer for function execution. Args: run_now (bool): If True, the function is executed immediately before starting the timer. """ deffunc_wrapper(): self.func(*self.args, **self.kwargs) self.start()
# Create an instance of SetInterval to run 'my_function' every 5 seconds timer = SetInterval(my_function, 5, args=['Hello, world!'], kwargs={'severity': 'DEBUG'}, run_now=True) # Output: [DEBUG] Hello, world! # To cancel the interval timer.cancel()
Advantages and Considerations
This implementation offers a robust way to handle periodic function execution in Python. It’s particularly useful in scenarios where you need a simple, lightweight timer that doesn’t block the main thread. However, it’s important to note that this approach uses threading, which may not be ideal for CPU-bound tasks due to Python’s Global Interpreter Lock (GIL). For I/O-bound tasks, it should perform well.
Conclusion
The SetInterval class provides a Pythonic way to mimic JavaScript’s setInterval functionality, offering an easy-to-use interface for periodic function execution within your applications. Whether you’re developing GUIs, working on a server-side script, or simply need to run periodic checks in your code, this class can be a handy addition to your toolkit.
I hope you find this implementation useful for your projects! Feel free to modify and adapt the code to fit your needs more closely. The GitHub-Gist for this code can be found here. Happy coding!
Sometimes you just need a practical scenario to dive into a new tech field. In my case, it was wanting to monitor my cat’s daily routine — when he eats and when he heads to the litter box. It wasn’t just about the curiosity of knowing his routine, but also ensuring he’s eating and doing his business as usual, which is a good indicator of a pet’s health. Also, I had a cheap webcam, I had no use for and, that was perfect for this endeavor which nudged me into the world of motion detection and object recognition, combining them to create basic yet effective pet monitoring.
All code referenced in this post, and more is available in the GitHub repository.
Object detection with YoloV8
Ultralytics, the creators of YOLOv8, made it available in 5 sizes: n, s, m, l, and x. The bigger the model, the more accurate it is, but it also requires more resources.
Since my finished code will run in a vm on cpu only, because I do not have any ai-accelerators or gpus in my hyper visor, I have to make a tradeoff. I cannot use the x-model, even though its accuracy is fantastic. The n-model allows for a usable frame rate but is too inaccurate for my use case. The tradeoff will be that I need to train the n-model myself to improve its accuracy for my use case.
How well each model performs on your specific device is easy to check. Take a look at this minimal viable example to detect objects in a video using yolov8s:
Step 1: install ultralytics, numpy and opencv
open a terminal and run the following command. You can also use a virtual environment if you want to, but at least for ultralytics it makes sense to install it globally, because of its command line interface.
1
pip install ultralytics numpy opencv-python
step 2: download the model
The models are available on GitHub. You can download them for free using curl or your browser.
We are using the *.onnx (pronounced onix) model here. This is a format optimized for even faster inference. You can convert the *.pt model to *.onnx using the following command:
1
yolo export model=yolov8s.pt format=onnx
step 4: run the model against a video
Now we can use the model to detect objects in a video. For this, we need a video file. You can use any video file you want. I used a video of my cat eating.
# helper function that will draw the box and label for each detection defdraw_bounding_box( img, class_id, confidence, x, y, x_plus_w, y_plus_h ): label = f'{CLASSES[ class_id ]} ({confidence:.2f})' color = colors[ class_id ] cv2.rectangle( img, (x, y), (x_plus_w, y_plus_h), color, 2 ) cv2.putText( img, label, (x - 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2 )
defmain( onnx_model, input_video ): # load model model = cv2.dnn.readNetFromONNX( onnx_model ) # load video file cap = cv2.VideoCapture( input_video )
# while video is opened while cap.isOpened( ): # as long as there are frames, continue ret, original_image = cap.read( ) ifnot ret: break
# the model expects the image to be 640x640 # the following code resizes the image to 640x640 and adds black pixels to any remaining space [ height, width, _ ] = original_image.shape length = max( ( height, width ) ) image = np.zeros( ( length, length, 3 ), np.uint8 ) image[ 0:height, 0:width ] = original_image scale = length / 640 blob = cv2.dnn.blobFromImage( image, scalefactor = 1 / 255, size = (640, 640), swapRB = True )
# actually feed the image to the model model.setInput( blob ) outputs = model.forward( )
# the model outputs an array of results that we need to process to transform the # coordinates back to the original image size, also we only want to consider detections # with a confidence of at least 25% outputs = np.array( [ cv2.transpose( outputs[ 0 ] ) ] ) rows = outputs.shape[ 1 ] boxes, scores, class_ids = [ ], [ ], [ ] for i inrange( rows ): classes_scores = outputs[ 0 ][ i ][ 4: ] ( minScore, maxScore, minClassLoc, ( x, maxClassIndex ) ) = cv2.minMaxLoc( classes_scores ) if maxScore >= 0.25: # only consider detections with a confidence of at least 25% box = [ outputs[ 0 ][ i ][ 0 ] - ( 0.5 * outputs[ 0 ][ i ][ 2 ] ), outputs[ 0 ][ i ][ 1 ] - ( 0.5 * outputs[ 0 ][ i ][ 3 ] ), outputs[ 0 ][ i ][ 2 ], outputs[ 0 ][ i ][ 3 ] ] boxes.append( box ), scores.append( maxScore ), class_ids.append( maxClassIndex )
# deduplicate multiple detections of the same object in the same location result_boxes = cv2.dnn.NMSBoxes( boxes, scores, 0.25, 0.45, 0.5 )
# draw the box and label for each detection into the original image for i inrange( len( result_boxes ) ): index = result_boxes[ i ] box = boxes[ index ] draw_bounding_box( original_image, class_ids[ index ], scores[ index ], round( box[ 0 ] * scale ), round( box[ 1 ] * scale ), round( ( box[ 0 ] + box[ 2 ] ) * scale ), round( ( box[ 1 ] + box[ 3 ] ) * scale ) ) # show the image cv2.imshow( 'video', original_image )
if cv2.waitKey( 1 ) & 0xFF == ord( 'q' ): break
cap.release( ) cv2.destroyAllWindows( )
if __name__ == '__main__': parser = argparse.ArgumentParser( ) parser.add_argument( '--model', default = 'yolov8s.onnx', help = 'Input your onnx model.' ) parser.add_argument( '--video', default = str( './videos/video_file.mp4' ), help = 'Path to input video.' ) args = parser.parse_args( ) main( args.model, args.video )
Fine-tuning and training the model
Training Yolo means to create a dataset and use a the yolo train command to start the process. A training set is basically a simple folder structure with JPG-Files and corresponding TXT-Files. The TXT-Files contain the coordinates of the objects in the image. You will also need a yaml file that contains the class names and the directories that contain the training data
Step 1: create the dataset
Let’s start by creating a folder structure for our dataset. We will use the following structure:
The labels are simple text files that contain the coordinates of the objects in the image in the format <label_nr> <x_mid> <y_mid> <box_width> <box_height> eg.:
Creating these label files is the actual part of training your model; it takes a lot of time and effort. But the effort is worth it, because the more accurate your labels are, the better your model will be. We have basically two options to create these labels: manually or automatically.
Manually creating labels
For some images I was not able to automatically label or where the automatic labeling was not accurate enough, I created the labels manually. I used LabelImg for this. It is a simple tool that allows you to draw bounding boxes around objects in an image and save the coordinates to file. It is available for Windows, Linux and Mac. Its also rather quick to work with when using the shortcut keys.
Automatically creating labels
Since we just want to improve the accuracy of the smaller n-model, we can use the x-model to automatically label the images. This is not as accurate as manually labeling the images, but it is a good starting point.
To start, I created a 5-minute video which always contains my cat in various locations in the scene. Running that video through the n-model, I collected all the images where the model was unable to detect a cat. I then ran these images through the x-model and used the resulting labels as a starting point for my manual labeling. Using an M1 Macbook, I was able to lable most of the ~7000 frames in about 1 hour.
For some frames, even the x-model was unable to detect the cat. Also, the x-model, in a few cases, drew the bounding boxes too big so that they included parts of the background. I manually corrected these labels.
You can find the code for both of these steps in the GitHub repository for this blog post:
detection_check.py: collects all frames where yolov8n was not able to detect a cat.
x_check.py: runs the frames from detection_check.py through yolov8x and saves the labels to file, creating a dataset in the process.
Step 3: create the training.yaml
This is just a simple config file for the training process. Assuming your folder structure is like the one from step 1, it should look something like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
path:./dataset train:images val:images# ideally you would have a separate validation set
epochs: the number of epochs to train for, epochs are basically iterations over the entire dataset. The more epochs you train for, the more accurate your model will be. But training for too many epochs can lead to overfitting, which means that the model is too accurate for the training data and will not be able to generalize to new data. Common wisdom is to train for as many epochs as you can without overfitting. In my case, I trained for 10 epochs, which took about 12 hours on my M1 Macbook.
In the end, I used a more complex command to make use of the “hyperparameters”, which resulted in a much more confident model. This is the command I used:
Now that we have a trained model, we can use it to detect objects in images and videos. The code for this is very similar to the code we used to create the training data. You will just need to exchange the label-writing part with whatever you want to do with the detection.
In my case, I monitored an RTSP stream from my webcam using OpenCV. And each time my cat is detected, we make an entry into the database so it can we display as a Gantt-Diagram. Because the ai-model is quite cpu intensive, I also implemented motion detection to only run the model when there is motion in the scene. This is the code I used:
# OpenCV offers a background subtractor that can be used to detect motion in a scene. Depending on the history-size, # it has some ramp-up time until it's reliable, so the first few iterations will result in false motion detection positives background_subtractor = cv2.createBackgroundSubtractorMOG2(history=500, varThreshold=25, detectShadows = False )
defmain( onnx_model, input_video ): # load model model = cv2.dnn.readNetFromONNX( onnx_model ) # load video file cap = cv2.VideoCapture( input_video )
# while video is opened while cap.isOpened( ): # as long as there are frames, continue ret, original_image = cap.read( ) ifnot ret: break
Machine learning is extremely powerful and fascinating, but the surrounding math makes it intimidating and unapproachable for the uninitiated. Though, with the right tools, it is easy to get started and create something useful. I hope this blog post was helpful to you, and you will be able to create something with it. If you have any questions, feel free to reach out to me on LinkedIn or GitHub.
Browsing the web and using services often requires us to give out our email address. And in the day and age of regular data breaches, we should be careful with what we give out. Apart, many services will hold on to your email address forever and use it for marketing purposes, even if you don’t want it, or tell them to stop.
For this use case services were invented that allow us to create a temporary email addresses, that will forward all emails to our real email address or allow us to read and answer emails in a webclient. Some are paid, some are free. But all of them have one thing in common: They are not open source, and you have to, again, trust them with your data. Some time ago I stumbled upon this repo on GitHub. It’s a CloudFormation template that will deploy a disposable email service in your AWS account. Sadly, it’s not maintained anymore, lacks some features and relies on, as said, a CloudFormation-Template. So I decided to take the idea and build my own version of it, using the AWS-CDK.
How it works
We will utilize several AWS services to build our service. It will be all serverless. The frontend will be a static website hosted in S3, the actions triggered be the frontend will be handled by several lambda functions through an API Gateway that is protected by a Cognito User Pool.
Receiving of emails ist done by SES for which you will need to create a custom domain and verify it, before you can start this project. Two lambdas check the incoming email, and if it is for a disposable email address, we save the email to S3 and note it in a DynamoDB “Addresses”-table. The frontend will then be able to read the emails from S3. If redirect is enabled for the disposable email address, the email will be forwarded to the real email address. When doing so, we replace the original sender with a proxy address so that you can answer redirected emails directly form you email client and still keep your real email address private.
Features
Create disposable email addresses
send and receive attachments
Forward emails to your real email address automatically
Reply to forwarded emails directly from your email client and keep your real email address private
fully fledged webclient to manage your disposable email addresses
comprehensive wysiwyg editor to compose emails
Prerequisites
AWS Account
Domain that you own and can create DNS records for
ideally you should have a subdomain for this service, e.g. disposable.yourdomain.com
configured SES and verified for that domain
Getting started
Install dependencies
If not already done you can install CDK as follows:
change the variables for the backend to fit your account and domain:
1 2 3 4
# edit the following files: $ disposable-email-cdk/lib/constants.ts # if your SES is not in eu-west-1, change the region in $ disposable-email-cdk/bin/disposable-email-cdk.ts
build the CDK project:
1
$ npm run build
deploy the CDK project:
1
$ cdk deploy
in case of errors, try to run:
1
$ cdk bootstrap
As already described, the frontend and backend are secured by a cognito user pool. The React-frontend uses an Amazon-library for authenticating with the pool, but we need to tell it which pool to use. For this we need to get the user pool id and the client id. You can find them in the AWS Console under Cognito -> User Pools -> Your Pool -> App Clients. Copy the id of the app client and the user pool id and paste them into the .env file of the frontend. Also copy the api gateway endpoint and enter the email domain.
1
$ disposable-email-frontend/.env
Now we can build the frontend as well and copy the build artifacts to the StaticWebsite-directory in the CDK project:
1 2
$ npm run build $ cp -r build/* disposable-email-cdk/src/StaticWebsite
finally we just deploy the thing again. don’t worry cdk is smart and skips unchanged resources:
1
$ cdk deploy
After deployment
After the deployment is finished, you can open the frontend in your browser. Though you will find that you don’t have credentials to log in yet. For security reasons I disabled the option of self-signup. So you will have to create a user manually. You can do so by heading back to AWS Console and going to the Cognito User Pool. Creating an Account is straight forward, so I won’t go into detail here. When you now first login with your new account, you will be asked to change your password using a token that was sent to your email address. After that you can log in with your new password. Also check your SES settings and verify that the correct rule set is selected. If not, select it and save the settings.
Conclusion
With this project you are now able to run your very own disposable email service. It can save you real money if you, like me, were paying for a service like this. And you can be sure that your data is safe, as you are in full control of it. Regarding cost, most expensive part is the hosted zone which will cost around $0.6/month. But if this service is just a subdomain more for you, than the cost are negligible, and you can run it basically for free, as long as you don’t have a ton of users. I hope you enjoyed this project. I had a lot of fun building it. If you have any questions or suggestions, feel free to contact me via GitHub.
When we monitor stuff we depend on the monitored device to be at least a bit cooperative. And while most business devices, we are used to, have no issues getting surveilled in one way or another, especially consumer devices tend to be difficult.
In my homelab I have such a device, a German Telekom issued Speedport Smart 3
In part 1 of this blog post we go into detail on how to monitor a Speedport Smart 3 with Nagios and in the upcoming part 2 we build an event handler to automatically react to events like low download speed.
Situation
In germany, ISPs have to provide you with a free modem when you rent an internet connection from them, the free solution for the Telekom is the Speedport. It is a fairly good device delivering most a consumer could wish for. It is not just a simple Layer 2 modem, it is also a router with DHCP, DNS, Wi-Fi, and some smart home capabilities. But since my home lab covers all these features, I usually put these provider issued devices into modem-mode (or as close to it as possible), and connect it to my firewall which does PPPoE or what ever is needed by the provider to get a connection.
Normally that’s it, the device is dumbed down and does not respond to anything else. But the Speedport Smart 3 has a nice feature that allows one device to connect to either of Port 1-3. When this device assumes an 169.254.2.0/24 IP we can reach the Speedport under 169.254.2.1 and get a nice overview of the reported, theoretical connection speeds and also some meta information about the Speedport.
So I connected port 2 of the Speedport to a free interface of my firewall, gave the interface the appropriate IP and also, since 169.254.0.0 is a Link-local address and normally not routed by network devices, I used the proxy-feature of my firewall to make the Speedport accessible to the rest of my network.
How it works
To monitor the Speedport we have to write a custom nagios check since the data are not easily extracted from the UI the Speedport provides. For some reason the JSON, the frontend receives from the Speedport, is encrypted. But since the password for it is also found in the frontend code, we can decrypt it but that is not something a standard check, nagios is shipped with, could do. Why it was build like this, with encrypted traffic but decryption keys in user accessible code is not known to me. I suspect an approach of security by obscurity.
Make Speedport service interfaces reachable
before nagios would be able to reach the Speedport’s service interface, we need some network magic done. I have done it two ways in the past. With routers that support routing link-local addresses you could just create a static route for 169.254.2.1 where you set the next hop to the routers interface that is connected to the speedport.
Since this has some security implications als also is not supported by my current firewall, a pfSense, I defaulted to use the integrated HA proxy feature.
Since my pfSense is virtualized, I first created a new virtual interface that terminated to a free physical interface of its host. The pfSense interface was configured to use 169.254.2.2
I then created a front end and backend in the HA proxy settings to make the speedport reachable to my server vlan, using the pfSense IP and port 8080.
For details on how to create a working proxy configuration for HA proxy, please refer to the pfSense Docs.
Preparing Nagios
First, let us create the Nagios check. I wrote it as a python script, and it can be downloaded from this project’s GitHub repo
Copy check_speedport_connection to /opt/nagios/libexec/
make sure that your nagios host has python3 and all the requirements installed
python3 -m pip install pycryptodome requests
For installing python consult your OS’ manual.
Now we need to teach nagios how to use our new script, In your commands.cfg, normally located at /opt/nagios/etc add:
Note: we could go really over board with defining the check here, but it’s really not necessary and also makes the syntax for using the check in the service config later on way harder.
At last, we need to actually use the check for a service. I have for each host I monitor one file containing all its service definitions.
define service { host_name Speedport 3 service_description Online state use generic-service,graphed-service check_command check_speedport_connection!--hostname x.x.x.x --port 8080 --downloadWarn 178000 --downloadCrit 160000 --uploadWarn 23500 --uploadCrit 19000 max_check_attempts 2 ## event_handler fix-internet ## we will be doing this in Part 2! check_interval 1 retry_interval 1 check_period 24x7 notification_interval 60 notification_period 24x7 contacts nagiosadmin }
Now only restarting Nagios is left either using the UI or from terminal. After some time Nagios should start to show the state like this:
The service check also emits performance data which can be viewed by clicking the little graph symbol next to the service name.
Now You will always know when your internet speed falls below your contract’s limits. Keep in mind that this is the actual reported value from the Speedport that would also be used by Telekom support in case of disputes. By collecting e-mails or even the performance data, you have a nice source of truth.
In Part 2 we will build an event handler that is able to restart the modem using a smart home power plug. Stay tuned.
DynDNS enables us to great stuff. I use it to reach my home network on the go via a neat subdomain. Sadly, many DynDNS provider call for some kind of fee, at least if you want to use your own domain. Good thing there is AWS, with its services Route53 and Lambda. AWS-Labs even has the working code in a GitHub repo for us but setting it up with the AWS Web Console can be tedious at best and a nightmare to maintain.
Since they posted that example much has changed in the AWS world. For example, we got the AWS CDK which makes it possible to write infrastructure as code using typescript and npm. Which in turn makes deploying stuff into AWS repeatable and easy.
So, today we are building an extensible, serverless DynDNS for your domain using CDK.
Let’s get started
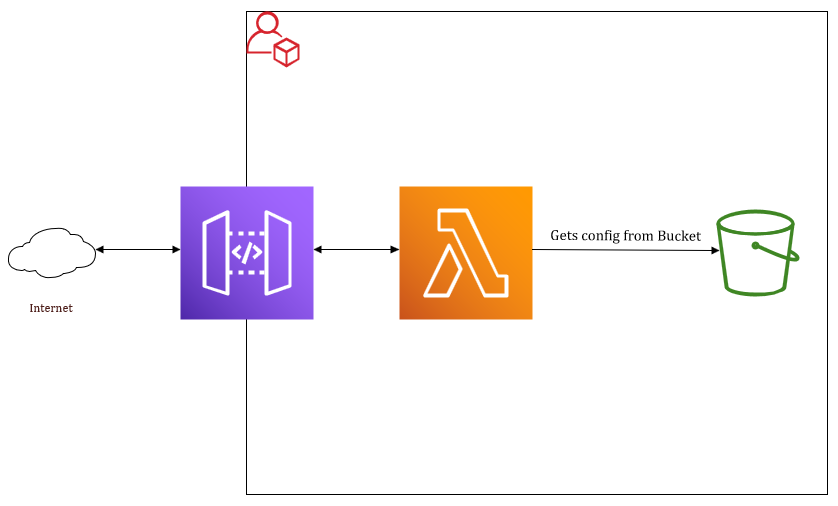
Before we start let us visualize what we are even building. We will be using AWS ApiGateway as the internet facing component. All requests will go to the APIGateway which in turn redirects it to our Lambda. The Lambda function will try to access the config file from the bucket and if successful it will do its magic.
How it will work
The DynDNS will be able to manage multiple zones and subdomains, depending on the configuration. For this example however, we are only making it to update one Record in a single Hosted Zone, but configuring it to do more is trivial.
The service will have two modes set and get.
The get-Mode will return the requesters IP as a json and is quite neat for all kind of programmatic applications where you have to get your external IP. ex. https://dyndns.mydomain.com/?mode=get
The set-Mode will take 2 URL parameters hostname and hash. hostname will contain the record you are trying to update with your new IP and hash will contain, well, a hash from the combined hostname, your external IP and the shared secret. Since the Lambda will have these values accessible inside the S3 Bucket, it can calculate the same hash we send it, and if so that means our request was “authorized” and the IP can be updated with the requesters. ex. https://dyndns.mydomain.com/?mode=set&hostname=home.mydomain.com.&hash=d37433e52b3d945eb7cdb63c75154a62f8ebacdf4dc62fe809a341bfbe201c23
Install prerequisites
If not already done you can install CDK as follows:
For convenience, I created a repo containing all the files we need. So Only some minor changes have to be done, and we can build and deploy the package.
We have to change 2 things, the Domain, CDK will use to deploy the DynDNS, and the config file the Service will use during runtime.
On line 18 in lib/dyndns_lambda-stack.ts enter the name from the hosted zone that should be used to make the service reachable. So if You plan to use dyndns.mycooldomain.com you already should have a Route53 Hosted Zone called mycooldomain.com.
Adjust the setting to fit you: src/lambda_s3_config/config.json These setting will be used by the lambda during runtime to generate the hash which will have to match the hash we send on our set-request. Do not forget the trailing dot for the domain name (it is not a typo).
Deploy
When done we can actually deploy our service to AWS. It is done in 4 steps.
Install dependencies
1
$ npm install
Translate files to js
1
$ npm run build
Synthesize a cloudformation template
1
$ cdk synth
deploy it to your AWS Account
1
$ cdk deploy
And Now?
And now we have a working DynDNS service which will update our Route53 Records to the IP requesting the change, if the authorization was successful.
From here on you could build a Cron job or something to call the script every x minutes to update your record. I do this from my home automatization server.
Pricing of this solution is extremely low. Only the Hosted Zone will cost a fixed price once a year and as long as you are using it privately, you will probably never hit the free tier limits and even then, it is cents to a million requests. For me, it never made the slightest dent in my bill.